VELMA: Verbalization Embodiment of LLM Agents for Vision and Language Navigation in Street View
Raphael Schumann1 , Wanrong Zhu2, Weixi Feng2, Tsu-Jui Fu2, Stefan Riezler1,3 and William Yang Wang21Computational Linguistics, Heidelberg University, Germany
2University of California, Santa Barbara
3IWR, Heidelberg University, Germany
arXiv PDF Code Tweet

Incremental decision making in real-world environments is one of the most challenging tasks in embodied artificial intelligence. One particularly demanding scenario is Vision and Language Navigation~(VLN) which requires visual and natural language understanding as well as spatial and temporal reasoning capabilities. The embodied agent needs to ground its understanding of navigation instructions in observations of a real-world environment like Street View. Despite the impressive results of LLMs in other research areas, it is an ongoing problem of how to best connect them with an interactive visual environment. In this work, we propose VELMA, an embodied LLM agent that uses a verbalization of the trajectory and of visual environment observations as contextual prompt for the next action. Visual information is verbalized by a pipeline that extracts landmarks from the human written navigation instructions and uses CLIP to determine their visibility in the current panorama view. We show that VELMA is able to successfully follow navigation instructions in Street View with only two in-context examples. We further finetune the LLM agent on a few thousand examples and achieve 25%-30% relative improvement in task completion over the previous state-of-the-art for two datasets.
Agent Workflow
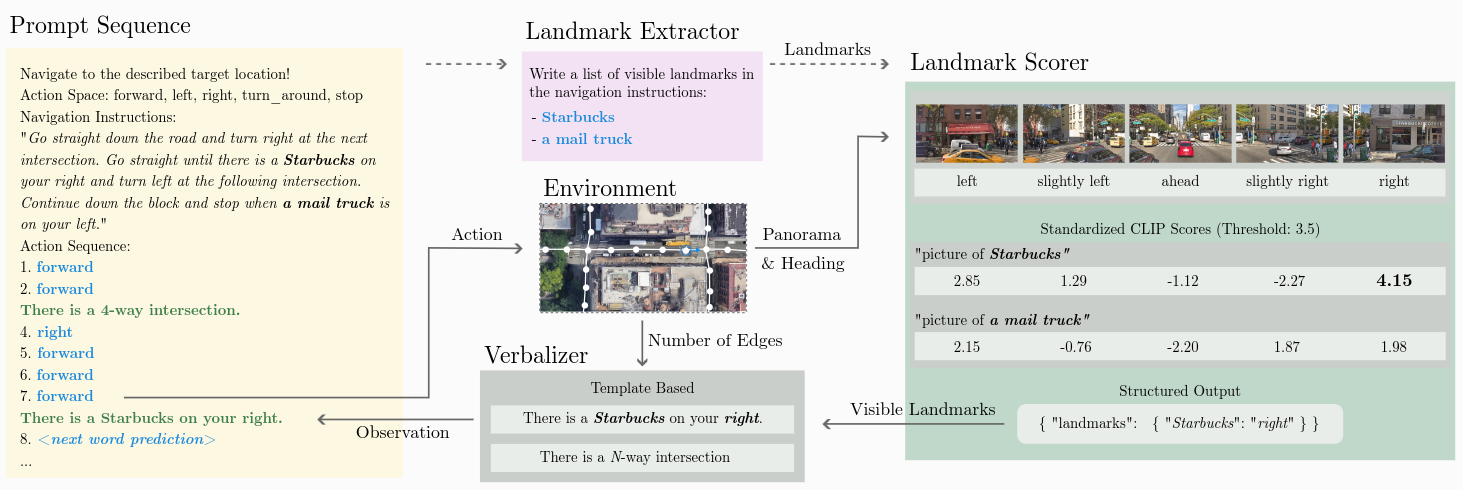
We verbalize the complete vision and language task, including task description, navigation instructions, agent trajectory and visual observations. At each step, the LLM is prompted to predict the next action, using the task verbalization as context. The action is then executed and new observations are appended to the prompt. This is repeated until "STOP" is predicted. If the agent stops at the intended target location, the navigation objective is successfully completed.
A separate prompt is used to extract all landmark phrases used in the navigation instructions. The landmarks can refer to any object or structure that is visible in the panorama images along the route.
The verbalizer is a template-based component that translates environment observations to text. The observations are either landmarks or an intersection. The observation text is appended to the prompt and used as context to predict the next action.
The agent operates in the commonly used Touchdown (Chen et al., 2019) environment. The environment is based on Google’s Street View and features 29,641 full-circle panorama images connected by a navigation graph. It covers the dense urban street network spanning lower Manhattan.
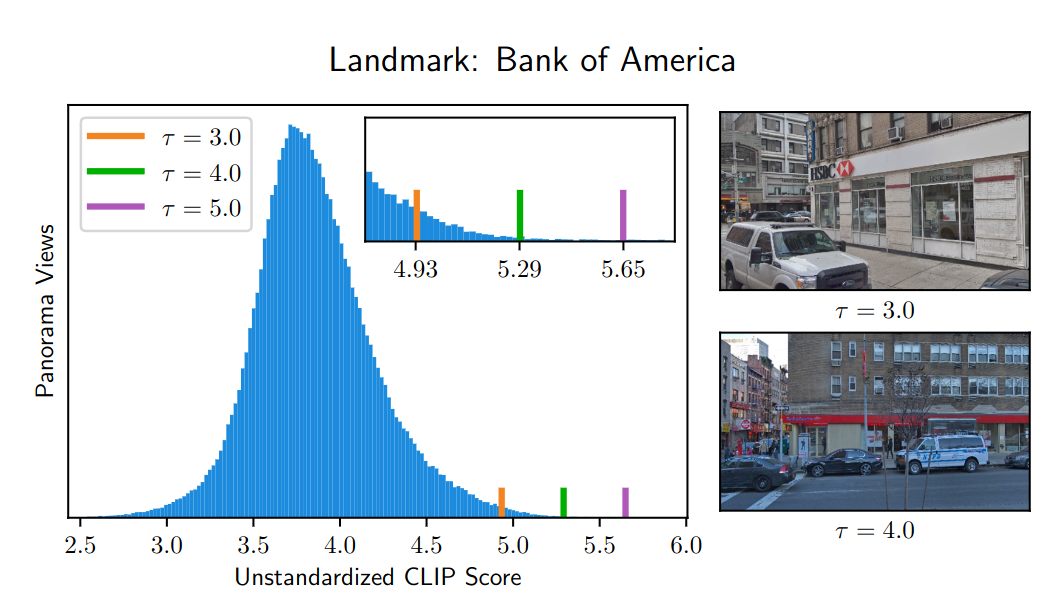
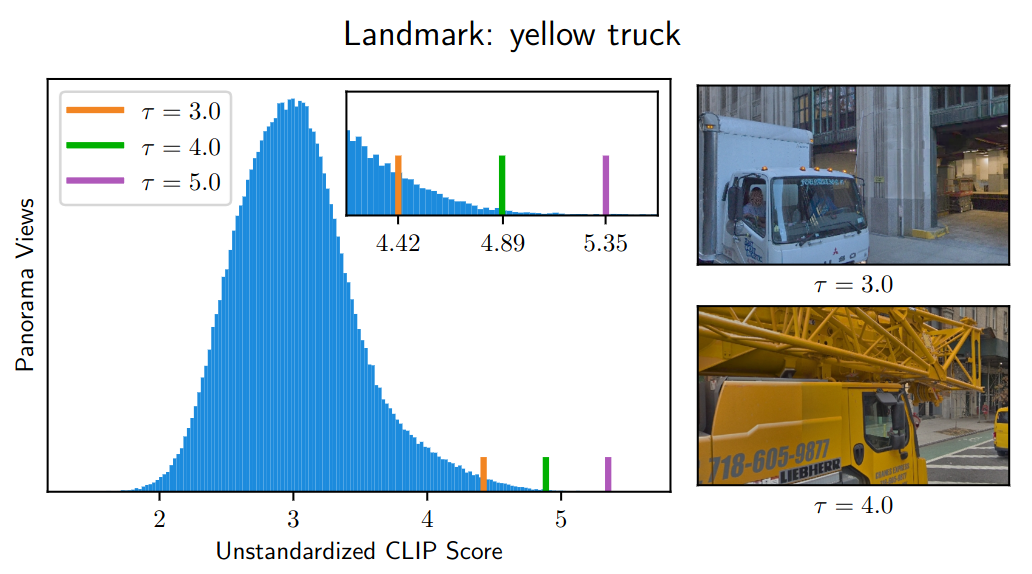
The landmark scorer determines the visibility of a landmark in the current panorama image. A CLIP model is used to embed the image and landmark phrase. If the similarity score between the two embeddings is above a certain threshold, the landmark is classified as visible in the image. The score is standardized using the score distribution over unused panorama images. We score the visibility over five different directions relative to the agent's heading and pass the visibility information to the verbalizer.
Citation:
@article {schumann-2023-velma,
title = "VELMA: Verbalization Embodiment of LLM Agents for Vision and Language Navigation in Street View",
author = "Raphael Schumann and Wanrong Zhu and Weixi Feng and Tsu-Jui Fu and Stefan Riezler and William Yang Wang",
year = "2023",
publisher = "arXiv",
eprint = "2307.06082"
}